

Introduction
Data lineage documents where data is coming from, where it is going, and what transformations are applied to it as it flows through multiple processes. It helps in understanding the data life cycle. It is one of the most critical pieces of information from a metadata management point of view.
From data-quality and data-governance perspectives, it is essential to understand data lineage to ensure that existing business rules exist where expected, calculation rules and other transformations are correct, and system inputs and outputs are compatible. Data traceability is the actual exercise to track access, values, and changes to the data as they flow through their lineage. Data traceability can be used for data validation and verification as well as data auditing. Data traceability and reconciliation is the process of evaluating that the data is following its life cycle as expected. [3]
Many governments require data reconciliation and lineage
European Union (EU) law requires that all financial firms conduct regular reconciliations of their front office records against financial databases and data integrations reported to EU regulators.
Due to EU obligations under MiFID II, (i.e., the EU Markets in Financial Instruments Directive 2004), significant data risk is inherent in data integration and reporting that can result in possible loss of BI “decision integrity”. All firms must implement a robust and flexible solution for data validation and reconciliation. MiFID II covers nearly the entire universe of financial instruments.
Data risk is an increasing problem in the financial industry that is owing to the number of processes data is exposed to between its source and its target destinations. According to MiFID II, reporting data may need to pass through many external firms’ databases before reaching regulators. Each step frequently includes both manual and automated data transformation and enrichment layers, potentially introducing errors.
The farther removed a transaction is from its final target, the higher the likelihood that errors will occur. It also becomes increasingly difficult to track these errors and reconcile data back to data sources (i.e., data lineage). The consequence is higher costs through manual data reconciliations and the potential for inquiries and penalties due to inadequate controls.
What are data reconciliation and data lineage processes?
Data reconciliation processes and tools are used during testing phases during a data integration where the target data is compared against original and ongoing transformed source data to ensure that the integration (e.g., ETL) architecture has moved and transformed data correctly. [2]
Data reconciliation is an action of:
- Conducting vital (quality) checks after data loads/ETLs: [2]
- Metadata correctness – sources to targets
- Data integration completeness – row and column counts
- Target data uniqueness – ex., no duplicate rows nor columns
- The referential integrity of both source and target data – ex., primary and foreign key relationships
- The correctness of data aggregations – source to target and transformations
- Comparing data points to detect errors in data movements and transformations
- Identifying data sets (e.g., source and target) where there should be no differences
- Comparing and verifying metadata from sources to targets (e.g., data types, data lengths, min/max values, precision, and much more)
Data reconciliation is central to achieving those goals. The stepped-up pace of the market and more demanding client expectations have made a high quality data reconciliation and data lineage assessment process a competitive necessity.
Candidate applications for data reconciliation can be based on these influences:
- The complexity of the data extraction processes (e.g., extraction of delta data vs. full load)
- Defined and ongoing human interventions
- Number of modifications to standard data extraction processes
- Frequent changes to business rules
Data lineage processes and tools help organizations understand where all data originated from, how it gets from point to point, how it is changed/transformed, and where it is located at any point in time. [2}
Through data lineage, organizations can understand what happens to data as it travels through various pipelines (e.g., spreadsheets, files, tables, views, ETL processes, reports). As a result, more informed business decisions will ensue. Data lineage clarifies the paths from database tables, through ETL processes, to all the reports that depend on the data; data lineage enables you to double-check all reports to ensure they have everything required.
Data lineage efforts enable organizations to trace sources of specific business data in order to track errors, implement changes in processes, and implement system integrations that will save substantial amounts of time and resources, thereby improving BI efficiency and “decision-making integrity”. Without data lineage, data stewards may be unable to perform the root cause analysis necessary to identify and resolve data quality issues.
Organizations can not advance without understanding the story of data that it uses continuously for decision making integrity. Data lineage gives visibility while greatly simplifying the ability to trace errors back to root causes n a data analytics process.[2}
Finally, data lineage is often represented visually to reveal the data flow/movement from its source to destination via various changes. Also, how data is transformed along the way, how the representation and parameters change, and how the data splits or converges after each ETL or incorporation into reports.
Example of DW/BI data lineage and reconciliations
Generally, data reconciliation for information systems is an action of:
- Comparing specific data points
- Identifying differences in source and target data points where there should be none
- Troubleshooting differences
Figure 1: Data warehouse ETL’s integrate product data from two sources: “Source A” and “Source B” (Figure 1), Each Source A and B record may have a different product number (Prod_num) for the same product name (ex., Mutual Fund A). [1]
In Figure 1, ETL’s create the “Data Warehouse” tables that allow for only one product number (Prod_num) per product. In case of a data discrepancy, the business rule is such that Source A‘s value will have precedence over the value from Source B.
Due to these implemented business rules, the Data Warehouse tables and BI reports will contain the Prod_num for product (Product: Mutual Fund A, Prod_num: 123) the same as in Source A, while the Prod_num from Source B will be logged as an exception – perhaps to be corrected in the future.
In Figure 1, the reconciliation of data between the Data Warehouse and the Source B Exceptions Log will be compared:
- Product Name and Product_num from the Source B Exception Log with the Data Warehouse tables
- For records that do not match, and the Prod_num from the Data Warehouse equals Prod_num in Source A, the reconciliation succeeds.
Note: If Product_num exceptions in Source B had not been captured and logged, Data Warehouse Prod_nums and BI reports would not all reconcile with those from Source A.
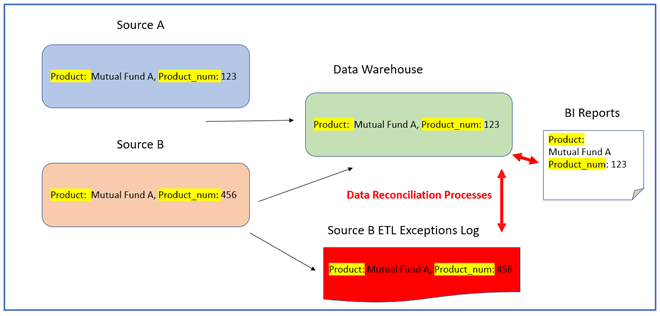
In this example, all reconciliation processes are concerned with the data in the final reports (together with all the ETL exceptions) are accurately reconcilable with the Prod_nums in Source A.
Conclusions
- Data reconciliation implementation efforts depend on the complexity of the data, the number of sources, and the number of metrics to reconcile. It is desirable to prioritize the metrics based on business requirements.
- Maintainability, supportability, and developing reconciliations to problem areas are some crucial matters that should be addressed by an IT support team.
- Data reconciliation is an often overlooked and undervalued activity, seen as a routine—albeit necessary. However, done correctly, reconciliation is crucial to two of the most important determinants of your organization’s success: front-office performance and client satisfaction.
- Unfortunately, reconciliation at many firms remains a laborious, time-consuming and risk-laden process, where the staff is forced to search through reams of spreadsheets and reconcile data manually.
- Automating reconciliation processes and implementing exception-based workflow best practices offers businesses easy wins in the quest for greater productivity, performance, and efficiency.
A few challenges prevent widespread deployment of data reconciliation systems:
a) securely and accurately generating data reconciliation information within the IT system
b) securely coordinating that collection within distributed systems, and
c) understanding and controlling the storage and computational overheads of managing such processes.
Editor’s note: Wayne Yaddow is an independent consultant with over 20 years’ experience leading data migration/integration/ETL testing projects at organizations including J.P. Morgan Chase, Credit Suisse, Standard and Poor’s, AIG, Oppenheimer Funds, IBM, and Achieve3000. Additionally, Wayne has taught IIST (International Institute of Software Testing) courses on data warehouse, ETL, and data integration testing. He continues to lead numerous ETL testing and coaching projects on a consulting basis. You can contact him at wyaddow@gmail.com.
References:
[1] Rachid Mousine, “Design Essentials for Reconciliation Data Warehouse”, Formation Data Pty Ltd.
[2] Wikipedia, “Data Lineage”, “Data Validation and Reconciliation”, Wikipedia.org
[3] Mark Allen, Dalton Cervo, “Multi-Domain Master Data Management”, Morgan Kaufmann (MK), 2016